Well, this is not for Digikam alone.
You should consider this as a guideline on how you can organize your digital photos in Linux (and the other one as well 😉 ) I am far from saying that this is the only way to do it, but I can assure you that it works and has proven to be efficient.
Some people copy their files from the camera or the chip to a folder on the harddrive – and that’s it. Some even don’t bother to work on copies of their original photos and alter the originals directly. To do that you must be either very good – or very stupid, because every mistake is fatal. And if you don’t apply non-destructive procedures there is no way back. Never.
But even if you have learnt the hard way that copies and backups (on external drives preferably) are good, you may wonder how to organize your possibly growing collection. If you don’t take more than 10 shots a year, don’t waste your time, but if you shoot a lot more, please read on.
This is not going to be a tutorial on managing tags and keywords and Exif- and IPTC-data. I just decribe my way of organizing my files on filesystem-level. This is only the first step. Of course I also tag my files and use the various tools in Digikam to sort, select, gather photos by different criteria. But even if I did not have these, I’d still be able to find quickly what I am looking for.
Three things are important:
1. I keep my raw data apart from the work-data. I even have them on physically different drives, so that in case on HD kicks the bucket, the other files are not concerned. I make separate backups of them.
2. I keep the sql-database of Digikam apart from both the raw-files and the work-files and do not save it on the same drive. I make a separate backup of it as well.
3. Once my raw photos are copied to a disk, they are untouchable. I always work with copies.
Yes, this means that I »waste« some space on my harddrives. But hey, if there is one thing that has become really cheap, it is disk-space. And redundancy is your friend. It means safety.
[pullquote author="Me"]SESO! Save early, save often![/pullquote]
Also I like to sort my files not only by year/date, which is sufficient for the originals, but additionally by the intended use: web, print etc., as this also determines, in which size/resolution/fileformat I save them. Again this means that several variations of a file exist side by side – but in different subfolders. It makes sense, as for example the gallery in my blog requires a different width/height than that on Deviantart or Flickr. For some I add frames, for others not. And of course prints need a much higher resolution/dpi than pictures for mere web-use. You get the idea…
To make the handling in Digikam easier, I prefer not to maintain one big collection with all files in it, but create several collections/albums according to what the photos are used for.
Sounds complicated? It isn’t, I assure you. The following diagram should be easy to read and understand.
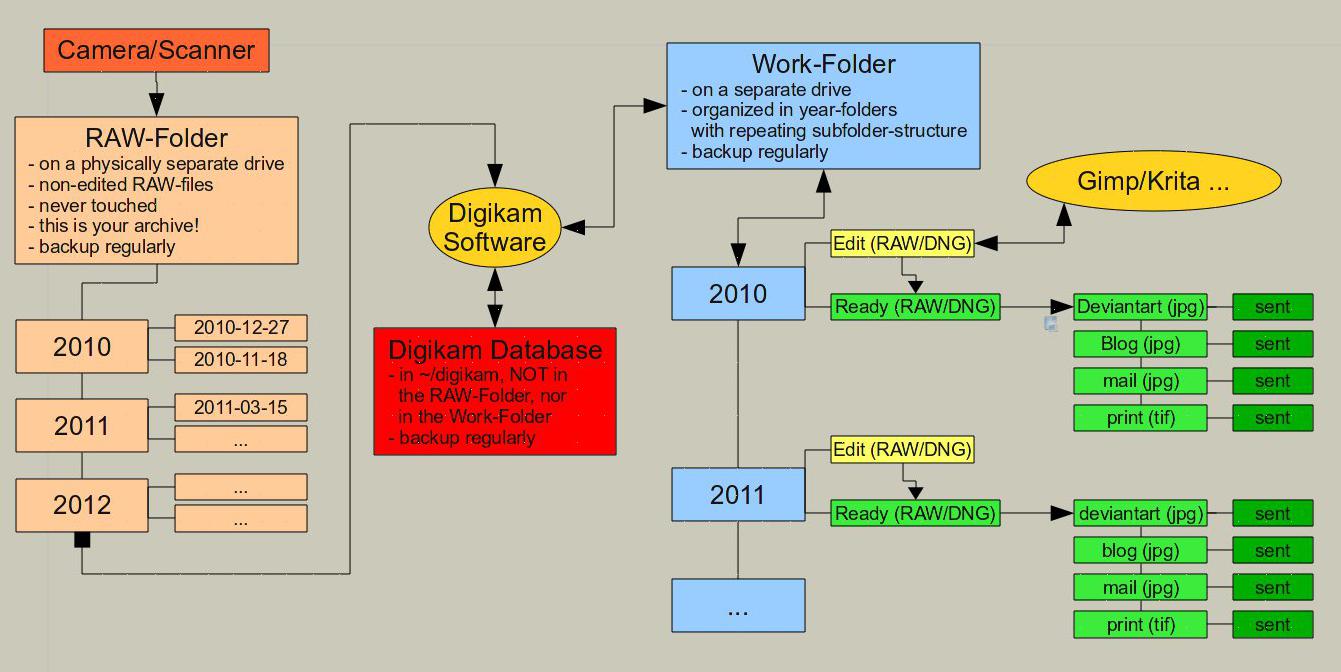
Don’t worry, if you use the import-tool of Digikam to download the files from your camera, it can create all necessary folders/subfolders for you automatically. Really easy.
ps. When I used the term »raw«, I did not only think of unedited photos, but had the technical format of the files from your camera in mind. If it allows you to I urge you to set your camera to raw-mode and not rely on jpg. Yes, the individual file will be a lot larger and it takes additional steps to edit them, but the results are worth it. Think of a raw-file as a »negative« like in the good old days. It contains all the data available – and not only those an engineer from your camera-factory thinks to be necessary.
Questions? Feel free to ask…
My workflow is similar. I separate my raw photos and original jpgs from a working folder broken down by date. I then use rsync to backup my whole /home folder to an external drive.
Rsync is awesome anyway. Do you know Luckybackup? It is a nice backend for rsync. Pretty slick.
You got me! I associate ‘workflow’ with the processing of RAW files, editing, cloning, cropping, etc., not with how to store them.
😉
Actually I am going to describe my »workflow« (the way you understand it) soon.
I agree that LuckyBackup is a terrific utility to use for file collections.
I think that L/B is a »front end« rather than a »back end« for rsync. One launches L/B, does the goo-ey (GUI) thing, and then L/B will create the rsync commands to accomplish whatever you asked for. In general L/B first … rsync follows. I think that a »back end« would use »rsync first … L/B follows«.
~~~ 0;-Dan
oh yes, correct, I mixed that up. 😉
I have a very similar system for my work-flow. You may be interested in reading about this tool I created for compressing my raw files efficiently. It saves me tens of gigabytes of space.
https://pclosmag.com/html/Issues/200801/page07.html
If you have any questions let me know.
I’ll check it out. thanks.
I do have backup at two different locations in order to safeguard against the inevitable. But since there is less space on the internal hdd of my laptop I prefer having only some of the albums / folders / directories on it. So can you give me some tips of how to organise partial redundancy?
I think the easiest way to deal with the limited HD-space on most laptops is to use the laptop as a »sluice«.
The data are pumped through it and your favourite editing software, tagged, categorized etc. and saved to an external HD. Or, which is my preferred solution, to a NAS (Synology, QNap, Buffalo…).
This external HD or NAS can then be backed up again, so your are on the safe side.
Afterwards you simply symlink the dirs that you want to see on it to your laptop. That way you don’t »waste« any space.
Thank you for an inside look of your photo workflow. Very helpful for many & much appreciated.
you’re welcome. I’m glad I could help.
Oh, Greeks need any help they can get anyway 😉